
 I’ve been thinking a lot about Major Incidents (MIs) lately. I guess this is normal considering it is my week in rotation as the Incident Commander (IC) for a company that manages one of the largest networks of hospitals, care centers, and clinics in the United States. To say that it is a high pressure role would be an understatement. Since IT MIs in a patient care environment can literally be a life and death situation, I’ve been wondering how we can ensure that the Major Incident process is as efficient and effective as possible.
I’ve been thinking a lot about Major Incidents (MIs) lately. I guess this is normal considering it is my week in rotation as the Incident Commander (IC) for a company that manages one of the largest networks of hospitals, care centers, and clinics in the United States. To say that it is a high pressure role would be an understatement. Since IT MIs in a patient care environment can literally be a life and death situation, I’ve been wondering how we can ensure that the Major Incident process is as efficient and effective as possible.
The Expanded Incident Lifecycle
The Availability Lifecycle book of ITIL v3 2011 has a good explanation of the Expanded Incident Lifecycle and goes into why it’s good to measure the timestamps at the various lifecycle milestones.
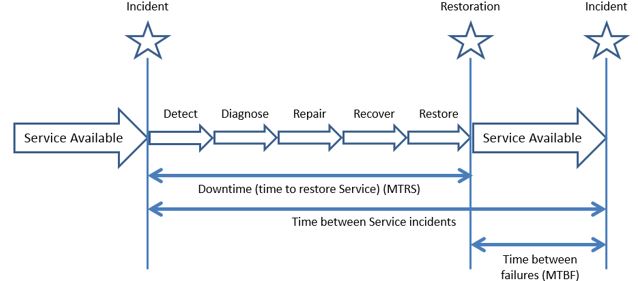
We want to measure the time between these milestones because they give us insight into where we might have inefficiencies in our normal Incident process.
Incident Occurring to Detection – Do we have adequate and well-tuned monitoring tools (or are our end users the only IT monitoring tool we have available)?
Detect to Diagnose – How good we are at troubleshooting issues?
Diagnose to Repair – How well our systems are engineered for serviceability?
Repair to Recover – What is the time it takes to bring functioning Services back online after the repair has been completed?
Recover to Restore – How long we require to test and QA our Services prior to giving them the green light and then to inform our end users that the Services are ready for use?
All these timestamps should, when averaged over time, allow us to optimize our Incident process, but there are some timestamps that I think are missing when measuring the efficiency of the Major Incident process.
Major Incidents
ITIL v3 2011 has relatively little information on Major Incidents other than to say that they have a separate procedures with shorter timescales. Of course every organization must define what conditions must occur for the Major Incident process to be invoked and for an MI to be declared, but once an MI has been determined, I think there are additional milestones that should be captured.
MI Determined – The delta between the Incident being detected and the MI being determined shows how efficient the Incident process is in determining the scope of the issue. Often very low priority Incidents simmer for a very long time before escalating to become Major Incidents.
MI Declared – How long does it take from determining that an Incident is significant enough to be called an MI until the powers that be actually invoke the MI process. A good example of an issue with the MI process would be if the Service Desk is being overwhelmed with calls, but for one reason or another, they neglect to reach out the IC to initiate the MI process.
Incident Commander Engaged – Are the Incident Commanders (the people responsible for coordinating the response to MIs) responding in a timely fashion? Are there automated mechanisms to page out to a secondary IC if the primary doesn’t respond within a pre-defined time period?
SMEs Engaged – This is how long does it take to get the needed experts engaged to work on the issue. I would further qualify this to be engagement of the correct SMEs. If the application goes down and you engage the appropriate app group, only to realize an hour later that you need the server or network team, then maybe your MI process should be requesting broader engagement when the MI is declared. Maybe for Priority 1 MIs there should be a predefined Incident Response Team (IRT) and have representation from all of the IT specialties paged simultaneously, regardless of the issue’s nature.
MI Notification Sent – Since MI notifications are fraught with political significance, many times the lag between declaring an MI and sending out the notification can be significant. I’ve seen the MI notification lag an absurdly long time as they get reviewed and rewritten by multiple managers and directors.
MI All Clear Sent – How long does it take to send out the all clear notification. I have been on MI bridges that continued for an hour after everything was completely functional (discussing what might have happened after the issue resolved itself) before it was decided that we should send the email informing the users that Services had been restored.
These additional timestamps would allow you to develop and focus continuous improvement projects on the effectiveness of the process responsible for responding to, what are by definition, the most business impacting Incidents.
Leave a Reply